
На выставке CES 2026 компания NVIDIA представила платформу Rubin, в основе которой лежит стоечная система Vera Rubin NVL72. Это третье поколение стоечной архитектуры NVIDIA, объединяющее шесть совместно разработанных чипов в единую систему. Платформа станет доступна у партнеров во второй половине 2026 года, при этом все шесть чипов уже вернулись с производства и в настоящее время проходят проверку с реальными рабочими нагрузками.
Vera Rubin NVL72: Шесть микросхем, одна унифицированная система
В видеокарте Vera Rubin NVL72 используется технология, которую NVIDIA называет «экстремальным совместным проектированием», при которой шесть различных чипов разрабатываются вместе, чтобы функционировать как единая система.

Процессор Vera: кремниевый чип ARM, разработанный для фабрик искусственного интеллекта.
Первым представленным чипом стал процессор NVIDIA Vera, демонстрирующий, как NVIDIA продолжает инвестировать в собственные ARM-чипы для задач искусственного интеллекта. Созданный на основе 88 собственных ядер Olympus ARM с полной совместимостью с Armv9.2, Vera разработан специально для задач перемещения данных и обработки данных агентами в современных фабриках ИИ. Он поддерживает соединение NVLink-C2C, обеспечивая пропускную способность 1,8 ТБ/с для графических процессоров Rubin, что вдвое превышает пропускную способность C2C по сравнению с предыдущими поколениями, и работает в семь раз быстрее, чем PCIe Gen 6. Процессор Vera удваивает производительность обработки данных, сжатия и компиляции кода по сравнению с процессором Grace предыдущего поколения.

Сравнение поколений: Blackwell Ultra против Vera Rubin NVL72
| Спецификация | GB300 NVL72 (Blackwell Ultra) | VR NVL72 (Вера Рубин) |
|---|---|---|
| Количество графических процессоров | 72 графических процессора Blackwell Ultra | 72 графических процессора Рубина |
| Количество процессоров | 36 процессоров Grace | 36 процессоров Vera |
| Ядра ЦП | 72 ядра ARM на каждый процессор | 88 ядер Olympus ARM на каждый процессор |
| Производительность вывода FP4 | 1,44 эксафлупс | 3,6 эксафлупс |
| NVFP4 на каждый графический процессор (вывод результатов) | 20 ПФЛОПОВ | 50 ПФЛОПС |
| NVFP4 на каждый графический процессор (обучение) | 10 ПФЛОПОВ | 35 ПФЛОПС |
| Тип памяти графического процессора | HBM3e | HBM4 |
| Пропускная способность памяти графического процессора | ~8 ТБ/с | ~22 ТБ/с |
| Поколение NVLink | NVLink 5 | NVLink 6 |
| Пропускная способность NVLink (на каждый графический процессор) | 1,8 ТБ/с | 3,6 ТБ/с |
| Пропускная способность NVLink в стоечном масштабе | 130 ТБ/с | 260 ТБ/с |
| Масштабируемая сетевая карта | ConnectX-8 (800 Гбит/с) | ConnectX-9 (1,6 ТБ/с) |
| Взаимодействие ЦП-ГП | NVLink-C2C (900 ГБ/с) | NVLink-C2C (1,8 ТБ/с) |
Графический процессор Rubin: Transformer Engines, NVFP4 и HBM4
Следующей звездой презентации стал графический процессор NVIDIA Rubin, оснащенный процессором Transformer Engine третьего поколения с аппаратным ускорением адаптивного сжатия. Это позволяет динамически регулировать точность на разных уровнях преобразователя, обеспечивая более высокую пропускную способность там, где точность может быть снижена, и сохраняя при этом точность там, где это важно. Эта реализация NVFP4 обеспечивает 50 петафлопс вычислительных ресурсов для инференции (в 5 раз больше, чем у Blackwell) и 35 петафлопс для обучения (в 3,5 раза больше, чем у Blackwell). Графический процессор Rubin — первый, в котором интегрирована память HBM4 с пропускной способностью до 22 ТБ/с, что является значительным шагом вперед и решает проблему ограничения пропускной способности памяти, с которой сталкиваются большие модели MoE.

NVLink 6: Связь «все со всеми» в стоечном масштабе
Коммутатор NVIDIA NVLink 6 удваивает пропускную способность на каждый графический процессор до 3,6 ТБ/с, а вся стойка обеспечивает масштабируемую сеть пропускной способности 260 ТБ/с — более чем в два раза превышающую общую пропускную способность глобального интернета. Эта масштабируемая сеть позволяет каждому графическому процессору одновременно взаимодействовать с каждым другим графическим процессором (что является необходимым условием для параллельной обработки экспертными задачами), при этом все эксперты должны обмениваться результатами в кластере. Встроенные вычислительные ресурсы в сети ускоряют коллективные операции и снижают перегрузку, разгружая задачи, которые в противном случае потребляли бы циклы графических процессоров.

ConnectX-9 SuperNIC: переосмысление масштабируемых сетевых решений.
Сетевая карта NVIDIA ConnectX-9 SuperNIC обеспечивает масштабируемость сети, предоставляя 1,6 ТБ/с пропускной способности RDMA на каждый графический процессор для связи за пределами стойки. ConnectX-9 была разработана совместно с процессором Vera для максимальной эффективности передачи данных и представляет собой полностью программно-определяемый, программируемый и ускоренный канал передачи данных, который позволяет лабораториям искусственного интеллекта внедрять собственные алгоритмы перемещения данных, оптимизированные для конкретных архитектур их моделей.

BlueField-4 DPU и защищенная архитектура ASTRA
BlueField-4 — это процессор обработки данных четвертого поколения от NVIDIA, представляющий собой фундаментальное переосмысление хранения данных и сетевых технологий для рабочих нагрузок искусственного интеллекта. Новый DPU оснащен 64-ядерным процессором NVIDIA по сравнению с 16 ядрами ARM Cortex-A78 в BlueField-3, обеспечивая в 6 раз большую вычислительную производительность. Он включает в себя интегрированный сетевой адаптер ConnectX-9 SuperNIC вместо ConnectX-7 в BlueField-3, удваивая пропускную способность сети до 800 Гбит/с. Доступ к хранилищу данных через графический процессор в 2 раза быстрее, чем в предыдущем поколении. Помимо улучшений характеристик, значимость BlueField-4 заключается в том, что он обеспечивает: новый уровень инфраструктуры хранения данных, разработанной специально для ИИ, который NVIDIA позиционирует как необходимый для масштабируемого агентного ИИ.

BlueField-4 разгружает процессоры Rubin, отвечающие за сетевые задачи, хранение данных и безопасность, позволяя им сосредоточиться на выполнении модели. Он полностью интегрирован в проверенную архитектуру NVIDIA Enterprise AI Factory и поддерживается экосистемой Red Hat, Palo Alto Networks, Fortinet и другими.
В BlueField-4 также представлена ASTRA (Advanced Secure Trusted Resource Architecture). Эта архитектура доверия на системном уровне обеспечивает единую точку управления для безопасного выделения ресурсов, изоляции и эксплуатации крупномасштабных сред искусственного интеллекта без ущерба для производительности.
Конфиденциальные вычисления по всей стойке
Vera Rubin NVL72 — это первая стоечная платформа, обеспечивающая конфиденциальные вычисления NVIDIA по всей системе. Конфиденциальные вычисления третьего поколения обеспечивают безопасность данных на уровне ЦП, ГП и всего домена NVLink, при этом каждая шина шифруется при передаче. Это решает растущую проблему среди предприятий и лабораторий ИИ, использующих собственные модели на общей инфраструктуре: возможность гарантировать защиту моделей, обучающих данных и рабочих нагрузок вывода даже при развертывании на системах третьих сторон.
Коммутатор NVIDIA Spectrum-6 Ethernet обеспечивает работу масштабируемых сетей Nvidia. Он построен на основе технологии 200G SerDes с интегрированной оптикой (CPO), обеспечивая коммутационную способность 102 ТБ/с и передачу трафика между стойками VR NVL72. Переход к CPO имеет важное значение. Благодаря интеграции оптики непосредственно в микросхему коммутатора, NVIDIA заявляет о 10-кратном повышении надежности, 5-кратном увеличении времени безотказной работы и 5-кратном повышении энергоэффективности по сравнению с традиционной подключаемой оптикой.

Повышение эффективности и снижение затрат для моделей MoE.
NVIDIA заявляет, что VR NVL72 обеспечивает в семь раз меньшую стоимость вывода больших моделей смешанных экспертов (Mixture-of-Experts) при той же задержке, что и Blackwell. Для обучения той же большой модели MoE за то же время требуется всего в четыре раза меньше графических процессоров. Платформа обеспечивает в 8 раз большую вычислительную мощность на ватт.
Эти улучшения отвечают требованиям моделей MoE, которые активируют лишь часть своих экспертов для каждого заданного токена. Такие модели, как Kimi K2 Thinking, используют 384 эксперта, но активируют только восемь за раз, что требует масштабной связи между всеми графическими процессорами. Сетевые возможности VR NVL72, обеспечивающие масштабируемость до 260 ТБ/с, справляются с этой задачей.
Беспроводная стойка, разработанная для масштабных задач.
В VR NVL72 используется модульная конструкция лотков без кабелей, вентиляторов и шлангов, в которой применяются только печатные платы и разъемы, а не внутренняя проводка. Вычислительные лотки соединяются с помощью разъемов с «слепым» соединением при установке в стойку, что исключает необходимость ручной прокладки кабелей. Единственными внешними соединениями являются два шланга для подачи и отвода жидкости, которые подключаются к блокам жидкостного охлаждения.

В предыдущих системах, таких как GB300 NVL72, на сборку одного вычислительного блока уходило приблизительно 100 минут. Каждое кабельное соединение представляло собой потенциальную точку отказа, что становится существенным при масштабе в сотни тысяч графических процессоров. Прокладка кабелей ограничивала пути охлаждения и занимала пространство, а вентиляторы добавляли механическую сложность и шум.

Новая конструкция сокращает время сборки и обслуживания в 18 раз. Платформа также включает в себя механизм RAS (надежность, доступность, ремонтопригодность) второго поколения, охватывающий GPU, CPU и NVLink, обеспечивающий проверку состояния в реальном времени, отказоустойчивость и профилактическое обслуживание. Коммутационные лотки NVLink теперь поддерживают обслуживание без простоев, позволяя стойкам оставаться в рабочем состоянии, даже если коммутационные лотки извлекаются или частично заполняются. При масштабе в сотни тысяч GPU эти улучшения в плане ремонтопригодности напрямую приводят к увеличению времени безотказной работы кластера и его производительности.
Эта архитектура позволяет создавать конфигурации с более высокой плотностью размещения компонентов в будущем. Это также является ключевым фактором для реализации ранее анонсированных стоечных конструкций Vera Rubin CPX, о которых мы рассказывали на AI Infra Summit , в которых в тот же вычислительный модуль в уже компактной конструкции добавляются графические процессоры для обработки контекста .
Платформа для хранения контекста вывода в памяти
На выставке CES 2026 компания NVIDIA анонсировала платформу хранения контекста вывода (Inference Context Memory Storage Platform) — новый класс инфраструктуры хранения данных, разработанной специально для кэширования ключ-значение (KV-кэш). Платформа работает на базе сетевых технологий BlueField-4 и Spectrum-X Ethernet. Она обеспечивает до 5 раз более высокую скорость передачи токенов в секунду по сравнению с традиционными сетевыми хранилищами, используемыми для контекста вывода, до 5 раз лучшую производительность на единицу совокупной стоимости владения (TCO), до 5 раз более высокую энергоэффективность и 20-кратное сокращение времени до получения первого токена. Аппаратное ускорение размещения KV-кэша в BlueField-4 устраняет накладные расходы на метаданные и сокращает перемещение данных, а Spectrum-X Ethernet обеспечивает высокоскоростную сеть с низкой задержкой для доступа на основе RDMA.

Эта платформа решает растущую проблему узкого места в выводе LLM: управление кэшем ключ-значение (KV). Модели Transformer используют механизм внимания, в котором каждый сгенерированный токен должен учитывать все предыдущие токены. Без кэширования это требует пересчета векторов ключ-значение для каждого токена, что приводит к сложности O(n²). Кэширование KV хранит эти предварительно вычисленные матрицы в памяти для повторного использования, снижая сложность до O(n). Проблема в том, что размер кэша KV линейно растет с длиной последовательности и размером пакета. Один диалог с длинным контекстом может потреблять гигабайты памяти. В многопользовательских средах, обрабатывающих тысячи одновременных запросов в контекстных окнах, охватывающих миллионы токенов, память GPU HBM исчерпывается. Операторам приходится либо уменьшать размеры пакетов, либо сокращать контекстные окна, либо приобретать больше графических процессоров.
Традиционные сетевые хранилища не были разработаны для шаблонов доступа к KV-кэшу, которые требуют случайного доступа с низкой задержкой к потенциально терабайтам временных данных, распределенных по множеству одновременных сессий. Платформа Inference Context Memory Storage Platform предоставляет выделенный уровень хранения, оптимизированный для этой рабочей нагрузки, расположенный между GPU HBM и традиционным хранилищем. Это позволяет фабрикам ИИ масштабировать емкость контекста независимо от вычислительных мощностей GPU. Ранее мы рассказывали о том, как работает разгрузка KV-кэша с помощью NVIDIA Dynamo, используя ускоритель KV-кэша от Pliops. NVIDIA масштабирует его с помощью платформы NVIDIA Inference Context Memory Storage Platform и интегрирует в свой проект с открытым исходным кодом Dynamo. Это обеспечивает программную основу, которая объединяет дезагрегированные этапы предварительного заполнения/декодирования, интеллектуальную маршрутизацию и многоуровневую разгрузку хранилища этой новой платформы.
Партнеры по системам хранения данных, включая VAST Data, NetApp, DDN, Dell Technologies, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage и WEKA, разрабатывают платформы на базе BlueField-4. Они станут доступны во второй половине 2026 года.
Alpamayo: Физический ИИ на основе логических рассуждений для автономных транспортных средств
Компания NVIDIA анонсировала семейство открытых моделей искусственного интеллекта Alpamayo, инструментов моделирования и наборов данных, предназначенных для ускорения разработки безопасных, основанных на рассуждениях автономных транспортных средств (АТС). Семейство Alpamayo представляет собой модели, основанные на цепочке мыслей и рассуждениях, которые привносят человеческое мышление в процесс принятия решений в АТС. В основе этих систем лежит система безопасности NVIDIA Halo.
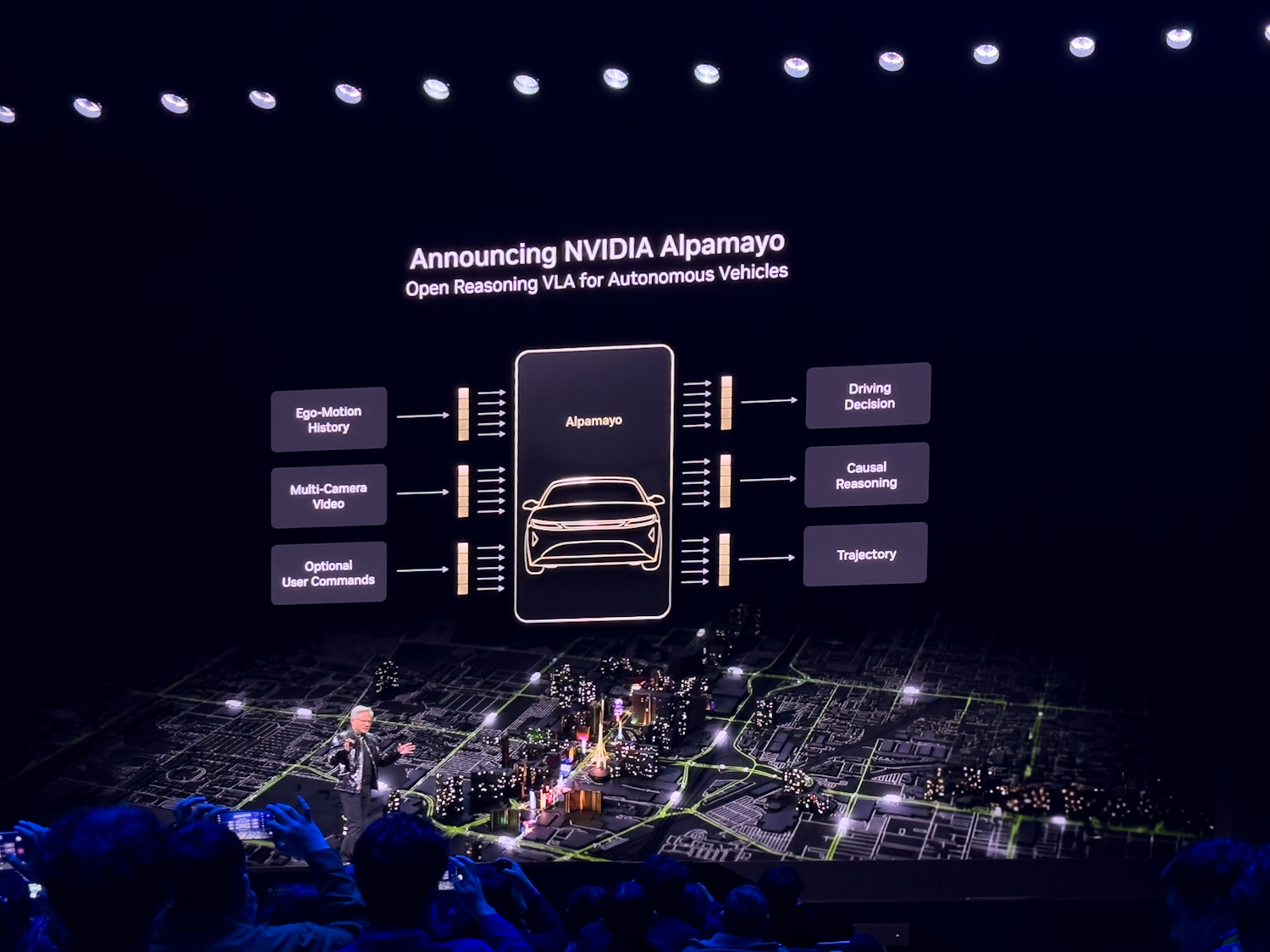
Традиционные архитектуры автономных транспортных средств разделяют восприятие и планирование, что может ограничивать масштабируемость при возникновении новых или необычных ситуаций. «Длинный хвост» редких, сложных сценариев остается одной из самых сложных задач для безопасного освоения автономными системами. Alpamayo решает эту проблему, позволяя моделям рассуждать о причинно-следственных связях, пошагово анализируя новые сценарии для улучшения управляемости и объяснимости.
Вместо того чтобы запускаться непосредственно в автомобиле, модели Alpamayo служат крупномасштабными обучающими моделями, которые разработчики могут дорабатывать и интегрировать в основу своих комплексных стеков для беспилотных автомобилей. Разработчики могут адаптировать Alpamayo в более мелкие модели для разработки автомобилей или использовать ее в качестве основы для инструментов разработки беспилотных автомобилей, таких как системы оценки на основе логических рассуждений и системы автоматической маркировки.
Alpamayo Models, Simulation, and Open Datasets
Alpamayo 1 — это первая в отрасли модель VLA с цепочкой рассуждений, разработанная для сообщества исследователей в области автономных транспортных систем и доступная на платформе Hugging Face. Благодаря архитектуре с 10 миллиардами параметров, Alpamayo 1 использует видеовход для генерации траекторий наряду с логими рассуждений, демонстрируя логику каждого решения. Alpamayo 1 предоставляет открытые исходные коды весов модели и скриптов вывода. Будущие модели семейства будут иметь большее количество параметров, более детальные возможности рассуждений, большую гибкость ввода и вывода, а также возможности коммерческого использования.
AlpaSim — это полностью открытая, комплексная платформа для моделирования высокоточных систем автономного вождения, доступная на GitHub. Она обеспечивает реалистичное моделирование датчиков, настраиваемую динамику дорожного движения и масштабируемые среды тестирования с замкнутым контуром, что позволяет быстро проводить проверку и совершенствовать стратегии.
В открытых наборах данных Physical AI Open Datasets содержится более 1700 часов данных о вождении, собранных в самых разных географических регионах и условиях, охватывающих редкие и сложные реальные ситуации, имеющие важное значение для развития архитектур логического мышления. Эти наборы данных доступны на платформе Hugging Face.
Разработчики могут точно настраивать выпуски моделей Alpamayo на основе собственных данных о парке техники, интегрировать их в архитектуру NVIDIA DRIVE Hyperion, построенную с использованием вычислительных ресурсов NVIDIA DRIVE AGX Thor, и проверять производительность в симуляции перед коммерческим внедрением.
NVIDIA DRIVE, резервные AV-стеки и Mercedes-Benz CLA
Компания NVIDIA работает над разработкой беспилотных автомобилей уже восемь лет, в её команде несколько тысяч человек. Компания создала полный стек: чипы (два Orin, два Thor следующего поколения), инфраструктуру (Omniverse и Cosmos), модели (Alpamayo) и прикладной уровень. Пять лет назад Mercedes-Benz заключил партнерское соглашение с NVIDIA для развертывания этого стека.
Первый полностью автономный автомобиль от NVIDIA, Mercedes-Benz CLA, поступит в продажу в первом квартале 2026 года в США, во втором квартале в Европе и в третьем/четвертом квартале в Азии. Euro NCAP присвоил CLA наивысший балл по активной безопасности среди всех автомобилей, представленных на тестирование в 2025 году. Каждая строка кода и каждый чип в системе сертифицированы по стандартам безопасности.

Система параллельно запускает два полных стека автономного вождения. Стек Alpamayo использует логику логического мышления и обрабатывает сложные сценарии вождения. Второй, классический стек автономного вождения, полностью отслеживаем и был разработан за шесть-семь лет. Специалист по политике и безопасности решает, какой стек использовать, исходя из уровня уверенности. Если Alpamayo сталкивается со сценарием, в котором она не уверена, система переключается на классический стек. Такое разнообразие и избыточность в программном обеспечении отражают подход к обеспечению избыточности оборудования в системах, критически важных для безопасности.
NVIDIA продолжит обновлять систему новыми версиями Alpamayo. Партнеры в сфере мобильности, включая JLR, Lucid, Uber и Berkeley DeepDrive, используют Alpamayo для разработки автономного вождения 4-го уровня, основанного на логическом мышлении.
Новые анонсы в области физических моделей искусственного интеллекта и робототехники.
Наряду с анонсами инфраструктуры и систем, NVIDIA также использовала CES 2026 для продвижения своей стратегии в области физического ИИ, выпустив новые открытые модели, фреймворки и периферийные платформы для ускорения разработки робототехники. Компания представила обновления своих моделей Cosmos World и моделей рассуждений GR00T для обучения роботов, а также новые инструменты с открытым исходным кодом (включая Isaac Lab-Arena) для крупномасштабной оценки роботов. OSMO — это платформа оркестрации от периферии до облака, разработанная для упрощения рабочих процессов обучения в гетерогенных вычислительных средах.

NVIDIA подчеркнула широкое внедрение своей робототехнической платформы в отрасли, и партнеры, включая Boston Dynamics, Caterpillar, LG Electronics и NEURA Robotics, продемонстрировали автономные машины нового поколения, созданные на основе технологий NVIDIA. Компания также объявила о более тесном сотрудничестве с Hugging Face для интеграции моделей NVIDIA Isaac и GR00T в открытую платформу LeRobot, что еще больше расширит доступ для мирового сообщества разработчиков робототехники.
На периферии сети NVIDIA подтвердила доступность модуля Jetson T4000 на базе процессора Blackwell, обеспечивающего значительное увеличение вычислительной мощности ИИ и энергоэффективности для автономных машин и промышленной робототехники. В совокупности эти объявления подтверждают стремление NVIDIA расширить свою полнофункциональную платформу ИИ за пределы центров обработки данных, охватив моделирование, вычислительные ресурсы на периферии сети и развертывание в реальных условиях в робототехнике и автономных системах.
https://www.storagereview.com/


